

This post is a transcript from Richard Lindsey’s keynote presentation at
The Austin Homegrown API Meetup in June 2019.
I am one of our principal engineers here at ShipStation. Developer experience (DX) has been kind of a favorite topic of mine for a long time and particularly when authoring your own API as it comes into play.
So a lot of people may not be familiar with the term DX, but they’re probably familiar with the term UX. So, DX is to developers what UX is to your users, and whereas UX typically has graphic designers, interaction designers, things like that, that help deal with how an application should look and feel, and they have their own best practices that they can follow, DX typically has its own best practices that should be followed, also. So engineers are people just like anybody else, and they’re the ones that are using your APIs, so they have their own motivations that can be appealed to.
So, I’ll start with one end of an extreme for an API. Webpack, how many people out there have used Webpack? It’s kinda trending… Hey Jesse. It’s kind of trending toward an industry standard, but it took a long time to get adopted because the API behind this thing is a nightmare. If you are not a power-user it takes a long time to figure out how to ramp up on that thing and how to configure it to do what you want it to do. Once you figure that out, it’s super powerful. So, as far as feature sets are concerned, it’s excellent, but it’s got a hard learning curve and so there was kind of a slow adoption for it.
On the other end of that extreme, you’ve got jQuery, which had a very expressive. Declarative API and it caught on like wildfire when it first came out. So, it’s got chainable functions, you can pass a selector in, get a handle to an element, or a group of elements and run a whole set of tasks against that thing, and it’s got plugin support, which led to jQuery UI for kind of a first round of web components. But along with that kind of ease of adoption also came no real opinionation behind the API. So, there were thousands of lines of spaghetti code out there. It was kind of a nightmare for people that were coming in and try to clean that up with later frameworks. So sometimes too flexible can also be a bad thing.
So, DX is important because as the previous example showed, products can live and die by their feature sets and the adoption rates. So, if you have barriers to entry, those can be kind of a hurdle for your users to get over and your users are of course other developers. So, if your API is difficult to consume, it’s not powerful enough, it’s not easy to retain, people are having to constantly go back and look at the documentation to figure out how to do what it is that they want to do there’s going to be fallout, and whenever possible you want to minimize that friction to adoption and make your API as easy to consume as possible for sticking factor out there.
“UX and DX are kind of interrelated. One is tailored toward users, one is tailored toward developers as the users.”
And UX designers typically use a variety of different ways to figure out what they want to shape their application for their own users. There’s user surveys, interviews, NPS feedback for scoring purposes, they conduct panels, and questions, and all sorts of stuff. So you should, as an API author, you should ideally try and find a way to interact with your own users to get that pulse check. That can be through issues on your GitHub repo, it can be through a support channel on IRC, or however you’re supporting this thing as a whole. If you notice the same questions are coming in over and over, maybe that’s a spot that needs improvement either in documentation or the API itself.
Designers should learn how their consumers are actually using their products. So a lot of times when we, if we crank out a UI, we expect it to work a certain way, and as the engineer’s behind that sort of thing it’s kind of easy for us to figure out how to do things, not always the case for our users. And the same thing can happen with APIs. We publish these things expecting that they work a certain way, but that’s not always how they’re used by the end users.
So interacting with your users can help you find where certain cruft can be taken out of the API altogether. Maybe nobody’s even using that functionality. Maybe you’ve got closely related items that can be combined. So those sorts of interactions can help you for road mapping purposes going forward.
And then as an example, the React team realized as they were moving from version 15 to 16 they were trying to get rid of a lot of the componentWill functions, but a lot of people were using those things to sync their internal component state with their incoming props. So, they didn’t want to scrap that functionality altogether, they gave a new function, to derive state from props that would kind of bridge that gap.
And this is one of my coworkers here, Joshua, I liked this quote:
“Make the change easy, then make the change.”
So, as an API author, if you’re going to be making any kind of changes to your API that are going to be public facing, you want to try and make migration paths as easy as possible for your users. And once you’ve made that simple, then it allows them to go ahead and make the change in their code.
Not all of your users are going to be power-users, they’re not going to be at the highest end of the spectrum. They’re also not going to be at the lowest end of the spectrum. They’ll always fall somewhere in the middle.
A good API should naturally encourage code that reads an expressive format.
Like your examples earlier, ‘get customer’, you can read that and know exactly what’s going on in the code. You don’t need additional documentation all the time.
By its very nature, it should be declarative, it should mask away some of the complexities, again, which you pointed out, if there are multiple calls going on behind the scenes whenever you call a certain function, your users don’t necessarily need to know about that. All they need to know is that they’re trying to perform a task and this function lets them do that task. It doesn’t necessarily matter how it gets done.
As an example, array sort methods are implemented in pretty much all languages out there. But how many people out there can tell with certainty that they know what kind of sorting algorithm goes on under the hood? Probably none and it really doesn’t matter. All you need to know is that you pass some kind of comparator function to it and you say when you compare this item to this item, either it moves up or down in the list. You don’t care how the efficiency is done under the hood. So that’s a method of declaring that thing through your array.sort call, but not necessarily caring how it gets done. If you really have to squeeze performance, like I say here, you’re probably going to write a custom function anyway that implements that.
So here’s some examples of kind of good versus bad versus middle of the road. Whenever possible we can write low level functions and write higher level functions that consumed them. This also called dog- fooding, or drinking your own champagne, or whatever. Some people like one term over another, but basically here we would start with a prop function, and give it a prop and an optional value, you either return a value or you set a value, and then we consume that with a couple of extra functions and these are just done for convenience sake. Similar to how your SDK is clustering other things for you. You’re just publishing something that’s a little more declarative for the users to consume, and they just chain through the underlying function. So you still, you publish the low level of stuff for other people to consume, but you also publish higher level stuff for people that don’t necessarily need that kind of power.
Whenever multiple functions share similar overlapping functionality, see if you can consolidate them.
I don’t know if anybody out there ever worked with MooTools versus jQuery, but MooTools has a couple of different entry point functions, there was single and double dollar sign, and the only difference between these things cause they both took some kind of identifier, but one of them would specifically return one node and one of them would return the collection of all the nodes that match it.
jQuery decided to go a different route and they said “Whenever you come into the dollar sign functions we’re always going to return everything that matches and then we’ll give you additional functions to pair that collection down if you actually need to only deal with a single one or you can pass a more specific identifier if you just want to get back a single node. But all of the functions that chain off of this thing will apply to everything in the collection.” There was no need to double the surface of that API for one or many.
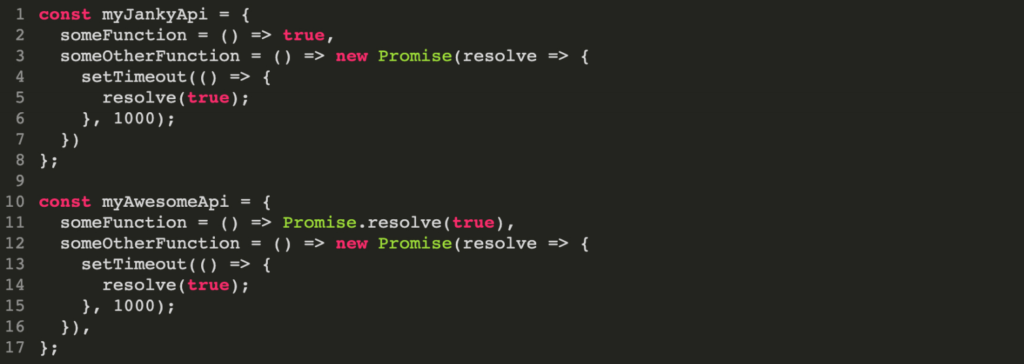
So, here’s another example.
Try to stick to a single paradigm for API inputs and outputs.
So we’ve got one example of an API that whenever the function is run, it just returns true. Another one that returns a promise. so it’s gonna be an asynchronous return that you’re going to have to await something to happen. In this case, it returns true also, but it does it a second later.
When you start writing code like this that mixes and matches synchronous and asynchronous calls, it increases the cognitive overload on your users, which means that over a large enough API surface they have to now remember which of these calls are synchronous and which of these are asynchronous, and which ones have to be a weighted versus return instantly. So, whenever possible, if you can pick a single paradigm and stick to it, then that’s ideal.
So to refactor this a little bit, we would just return a promise that resolves instantly with true, and then the other function is untouched, but now our users know that every time they touch this API they’re going to have to await the response. Whether it comes back fairly instantly or it takes a couple of seconds, they don’t have to remember that certain things returned certain ways. It’s always awaiting a response.
Future proofing your inputs: If you’ve got a language that allows you to do certain fun things, then you might as well make your functions extensible because you never know how your users are gonna use them. So why have a sum function that only takes two inputs and returns a sum when you can have a sum function that takes any number of inputs and returns the sum of all of them? Because if somebody has got a whole list of numbers, they’re trying to sum, you don’t want to make them run over a loop and pass them two at a time.
In another situation, we’ve got some parameters here on an original function. One of them is a default, so it has to go on the end. And then some new requirements come down the pipeline for this function—you’ve got an additional parameter that you have to insert somewhere, but whereas we can say for M4 here might only actually be used by 5% of the consumers, and everybody else can get away with the default, so they’re not bothering to pass it.
This other one, maybe there’s a switch statement inside that there’s a whole different variety of ways that this thing can use. So like 90% of your users are actually going to make use of that one. So you don’t want to put that on the end of the parameter list because then you’re forcing the 95% of the people that aren’t currently passing it to pass true. So, you stick it in the fourth position, but now everybody has to go through and stick this thing in the right position. And as you continue to expand this function signature in the future, you never know when people are going to put things in the wrong slot as they’re going through and refactoring code.
So, if you pass a single object that’s just basically a property bag of all of your parameters, then it really doesn’t matter where they stick it in because it’s just going to be a named parameter. So, whether they’re passing it or not, whether they stick it into the first position, or the fourth, or the third, anything, it doesn’t really matter. So it just helps them be able to migrate their code a little more competently. If you’re going to be passing like large signatures like this.
Don’t be afraid to add guardrails to protect your systems and your users.
Rate limiting or throttling can help protect your servers from getting hammered, but it really only protects past the point of entry to your servers. So, if you’ve got 100,000 people out there that are all running some client side application that hits your servers, and somebody does something stupid and they’re hitting it like a thousand times a second, you want to protect your servers against that kind of thing so that they don’t crash for everybody else. So, you can install some kind of rate limiting mechanism at the server. And this is kind of a naive implementation of one. We’re just setting max per second 20 and for every incoming request we’ve got a client ID. So, we’re just basically creating an entry in a map that tracks how many times they’re hitting it. And once a second we clear the map.
So, if at any given point we hit the max per second, we just start returning, “You’ve exceeded your plans rate.” And other than that, we increment it and we return whatever this potentially expensive operation is.
That works fine for the client. But again, it only happens past the point of entry. So, they’re still hitting your server all those times. If you really wanted to try and protect your systems from that sort of thing, you would also want to mirror something like this in your client side application to either batch incoming request from the client or rate limit them at the client.
And similarly, a user can also shoot themselves in the foot if they’re doing something that they didn’t anticipate. So, if you remember back in the jQuery days, you could grab a handle to an element, do .CSS, this property of this value .appendthischild, .all this other stuff. And a lot of people would write these massive chains of stuff, but under the hood, whenever jQuery would go to the apply those CSS settings, every time it writes into the style object, it’s causing a repaint operation in the browser.
So, if you have enough of these things going on, you can cause what’s called DOM thrashing, and basically the browser will start choking on all the updates that are going on and it will either drop animation frames so that any animations that are going on start becoming choppy, or it can start freezing the browser all together. You can have a second or two of Hangtime where the whole thing just kind of whites over.
Again, going back to our React example, because I’m in love with that team. A part of the allure of it is that at any given time your UI on the screen should be a representation of what your application state is at that slice in time.
So, one nice thing that React did was to take the timing mechanism out of it. So they handle how everything gets flushed at the DOM and you don’t have to worry about any of it. All you know is that whenever a certain user interaction occurs, you’re going to update your state and it will be reflected in the UI at some point. And that’s all you have to worry about.
React handles under the hood when that timing occurs, whether it’s on an animation frame, or some timed cadence, or some custom algorithm they’ve got implemented, and you’d be hard pressed to find a React dev that really misses having to babysit that timing mechanism. So, we’ve just gotten kind of pampered by not having to do that and it makes for a great guardrail.
So as an example here, we’ve got a dollar sign entry point, you pass an element to it and we called .CSS back to back a few times. To the average consumer, this may seem like an automic action, like they’re just calling it to set the background color of the margin and the padding, and all they know is that those three things are going to get done, but they don’t realize that under the hood as we’re writing into the style object that’s going to cause three different repaint operations in the browser.
If we expanded this a little bit for our users, we can allow them to not shoot themselves in the foot when they do things like this, and we can return a promise based solution that basically whenever you create this element entry. It queues it up in a weakmap, and then if we’ve got a promise already queued than it returns that promise for the promise getter, and otherwise it just queues up whatever you’re trying to do.
So we’ve got your incoming CSS calls will just get pushed into an internal array, and then we request an animation frame. When that animation frame comes through, we push all of those things through on CSS text at one time so it causes a single repaint operation and for the user it’s only a slight modification to how they might write their code instead of just calling this synchronously, they say await this action. Promise, and that’s it. And at any given point you can continue to add CSS calls, or remove them, and just” call.promise on the end and you’re good to go.
Inversion of control: also known as polymorphism or a few other names. Basically instead of being concerned over what type something is, you are concerned over what features that thing offers, or what kind of interface that thing offers. JavaScript, which is what all these examples are in, doesn’t have a true interfacing system, but we use what’s called duck typing. And so, basically all you care about from an implementation perspective is that if you’ve got a person that you’re passing into something, you should also be able to pass in a dog. If it’s like a speak kind of thing, as long as whatever you’re passing in offers a speak function, then it really doesn’t matter whether it’s a person or a dog.
So, you’re concerned more about what something has as opposed to what something is. And you can combine those with same defaults for your most common use cases.
As an example, we’ve got a piece of logger middleware. The constructor takes some kind of injected dependency, and in this case it’s just called logger, and it defaults to console if you don’t pass anything. So, you’ve got console.log, console. Error, and basically these functions that are exposed on the logger middleware are just proxies through to whatever the logger interface is. So we call it whatever the logger.log is, whatever the logger.error is, and we pass whatever the incoming arguments are.
So, that means that you can rely on console.log or console.error to fill that role. Or you can make up something custom. So if you’re using Century in production, you can create a Century logger that also implements log-in error and does whatever it’s going to do on those occasions. And then export a new instance of that. So then when we decided that we’re going to attach this as a piece of middleware, you can differentiate them by environment if you want. So, if you’ve got a default console logger middleware, which is just using the default console or the default logger middleware, which has console as its underlying logger, and we’ve got Century logger middleware that imports the Century logger and passes that to the constructor as its logger.
So, now whenever we’re going to spin up our app, if we are in production mode, we can require a Century logger middleware, and otherwise we can just require console.logger middleware and pass that on to whatever our logger chain is.
Further down the line, the consumers don’t need to worry about what’s actually being used for that. All they know is that they can call logger.log or logger.error and it doesn’t matter to them.
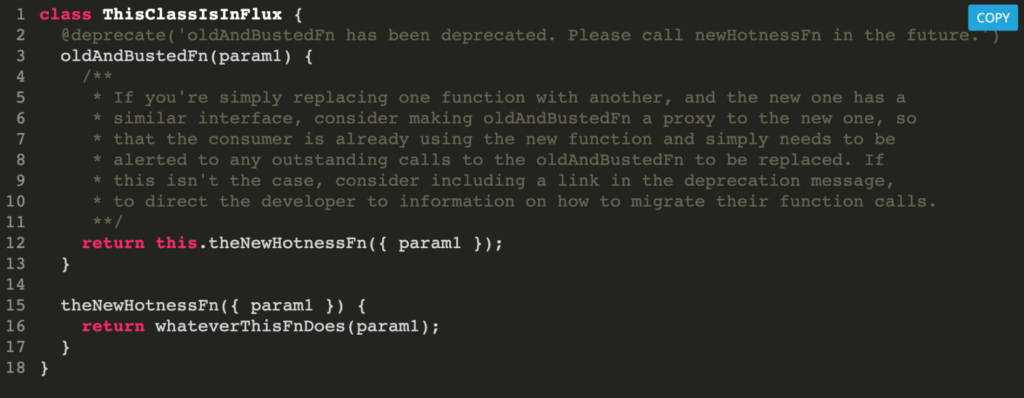
And then, decorators. If your language offers decorators, I’m a huge fan of decorators. It allows you to take some kind of predefined behavior or predefined functionality and package that up. You can unit test it on its own and you can then attach it to classes, or methods or properties within a class and get that kind of behavior attached for free basically.
So, in this case, we’ve got a class that we’re looking to migrate in some fashion. We’ve got an old busted function and we’ve got a new hotness function, and the only difference here is that the parameter signature has changed. So, in this case it’s pretty easy to chain one into the other, but we also want to make sure that we alert the engineer anytime they’re calling the old function that this is going to be deprecated and removed and some future iteration so they need to migrate their code.
So we just attach a deprecate decorator and it says “Old and busted function have been deprecated. Please call the new hotness function in the future.” And this allows them to easily be able to find those places in their code where they’re still calling those old functions and push them over to the new versions.
If you’ve got something that’s a little more expensive of a migration path you can also add documentation links here to tell them exactly how to migrate their code. You can explain why you’re making this kind of change in the first place. Whatever it is that you feel like your downstream consumers need to know can be added and removed as quickly as a simple line.
When authoring your own APIs, try and use a consistent interface because it makes composition a lot simpler.
If you’re using some kind of functional paradigm, you can easily just nest those things and use the risk return input of a chain into the input of another. If you’re using promise space, you can return entire chains of promises that just get awaited like everything else. It just makes it a lot simpler when you don’t have to do any kind of massaging of the data between one step and another.
And given a low level API, don’t be afraid to build your own custom APIs, which is basically what an SDK is, right? So, if you’ve got something low level, granular, maybe your power-users might make more use of that, but your common users, or public want something a little more friendly to interact with. So something that kind of packages up multiple things in one step for your common use cases, those are the kinds of things that you can build on top of those.
And think about your own favorite API experiences. The one thing that you have in common with anybody that’s consuming your API is that you’re an engineer and they’re an engineer. So if you are able to draw on prior experience, you know what you like, it will probably appeal to other people also.
One of the things that I wanted to kind of harp on here is; draw inspiration where it makes sense even if it feels derivative.
People kind of care more about the comfort, and familiarity, and predictable interfaces than they do about original thinking.
So, if you’ve got, like in the code examples that I’ve shown here, I’ve drawn a lot of experience from jQuery and a lot of the API examples are based on that sort of paradigm. It’s something that a lot of people have used, and it’s something that’s very predictable, and it’s something that’s very comfortable to use, as opposed to just something brand new that they’ve never encountered before that they’re going to have to go read documentation on in order to just dip a toe in the water, basically.
And then, this is an example of something that I’ve been working on for work. The Puppeteer API is what we use for a lot of our automated testing, but I think the API itself kind of sucks. So, I’ve been building something that’s a little more chainable based on like a jQuery paradigm.
So, we’ve got this element handle promise class that basically you have a single entry point to the sort of thing and then whenever you return from this, all of these functions are directly chainable, and at any given point along the way you can stop and await the response with that whole chain of functionality, as opposed to having to get a handle to an element, then await getting the value of that element, then await setting the value of something else. You can just do it all in one chain.
So again, it’s going to have some of the drawbacks of jQuery, in which people can write like long chains of things that that are very messy, but that’s the kind of thing we’ll just have to catch it in code review, or over time I might realize that maybe that’s a bad thing to have included in the first place and I’ll roll something back.
To sum everything up:
Good APIs should encourage well-read declarative code.
You should be able to scan through at a high level what somebody has written and know at a glance what their intent is whenever they wrote that code.
Minimize the API surface where you can. If you’ve got closely interrelated functions, try and combine them and just shrink the surface of the API that somebody has to remember in order to use your product.
Don’t be afraid to not reinvent the wheel. If you’ve got something that’s comfortable to work with that you’ve dealt with in the past, don’t feel like you have to do something just to be a snowflake.
Consistent interfaces are for predictability and composition. Try to make your interfaces inputs and outputs as consistent as possible. It’ll help people consume and deal with the outputs of those things in a more composable fashion.
And reduce the risk of foot guns anywhere you can. This is all about adding guardrails where it makes sense for yourself and for your users.
Unobtrusive messaging kind of hearkens back to the decorator functions that were being attached in order to tell your engineers that are consuming your product when things are changing and how to change their code.
And then dog-food or champagne, whatever your favorite metaphor is, use your own APIs yourself. Because if it’s a pain in the ass for you to use as the author, it’s going to be an even larger one for the people that you’re trying to get to adopt this.
View the video and slides from Richard’s presentation.
Want to learn more about APIs?
Join us for our next meetup!

About Author

Leave a Reply